Auto-Retrying API Calls Improves UX (Demonstrated In Node.js, Browser)
 Justin Etighe · 14 min. read
Justin Etighe · 14 min. read 
In the ever-evolving landscape of technology, user experience remains at the forefront of innovation. When it comes to applications that rely on networked services through APIs, ensuring a seamless experience is paramount. However, network issues are an unavoidable reality, and they often disrupt the essential API calls that power these applications.
Regardless of a backend’s design, whether it’s a monolithic structure or a microservices-based setup, they usually initiate numerous API calls to accomplish various tasks. In addition to internal services, third-party APIs are often employed to enhance the capabilities of these applications. It’s worth noting that in all these situations, API calls are vulnerable to interruptions in network connectivity. The challenge is prevalent across both the frontend and backend.
The question that arises is: how should we address these disruptions? Traditionally, users are presented with manual retry controls, such as the infamous “tap to retry” button or the “pull down to refresh” gesture, which they often have to repeatedly use in extremely poor network conditions. Have a look at the following screenshots from Instagram on iOS:
| Screenshot A (Internet disrupted) | Screenshot B (Internet restored) |
|---|---|
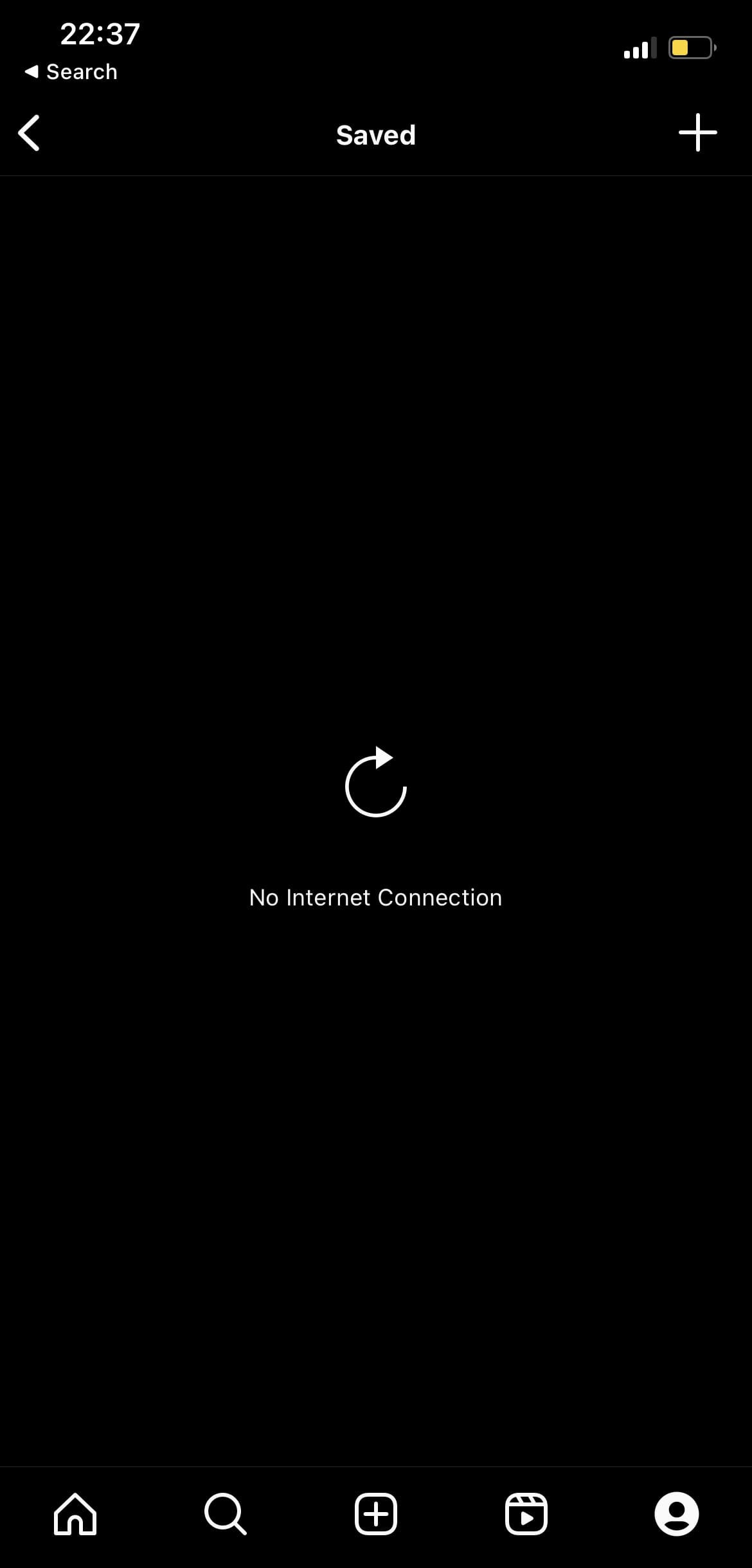 | 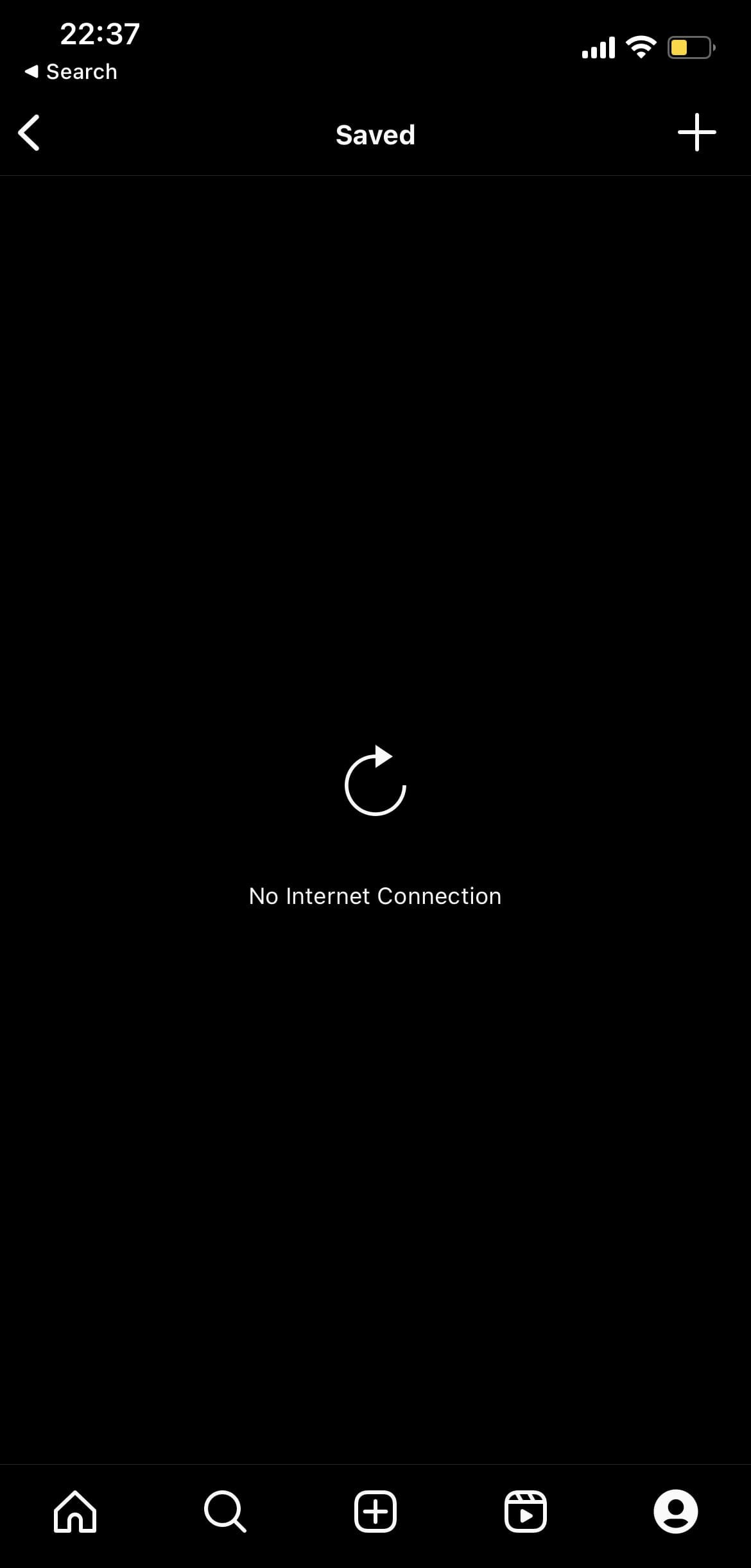 |
In screenshot A (left), I turned off my Wi-Fi and the cellular data while attempting to load saved content on Instagram. In screenshot B (right), I reconnect to Wi-Fi, yet I still have to manually retry the action by tapping the retry icon. This is a common issue in many apps.
Suboptimal network conditions can disrupt critical tasks or slow down the simplest of actions. Consequently, users of your app may become frustrated. Although you cannot enhance their network quality, you can alleviate their frustration by not requiring them to manually retry actions disrupted due to these conditions.
In this article, I advocate for perpetually retrying API calls, with exceptions made only when there are compelling reasons to do so. Of course, there are situations where automatic retries should not be employed, and we will discuss those as well. Additionally, to demonstrate the straightforward implementation of automatic retries, whether for new applications or existing ones, I will provide practical examples in JavaScript.
Situational Awareness
Before delving into the technical aspects of automatic retries, let’s establish why this approach makes sense. Typically, an API call is triggered by a user action, such as tapping a button to load a list of items. If this call fails due to the network issues, several key considerations come into play:
-
Deliberate User Intent: The user’s action triggering the API call was intentional. Network issues, which are often sporadic, thwarted their intention.
-
User Control: If the user accidentally triggered the action and wishes to halt it by disrupting their network connection, they can easily do so by exiting the app or navigating away. This effectively cancels any API retry attempts.
-
User Experience: Both user-triggered refreshes and automatic retries aim to fetch data from an API endpoint, something the user expects. Automatic retries, however, help prevent user annoyance during frequent network issues.
Automatic Retries
Given these factors, it becomes apparent that auto-retries are a user-centric approach to handling API call failures. Instead of burdening users with manual retry actions, applications can quietly and intelligently attempt to fetch the required data, improving the overall user experience.
To make this experience even smoother, consider displaying a message like “This is taking longer than usual. Please check your network connection while we keep trying.” when an API call fails. This informs the user that the issue might be on their end and avoids the misconception that the app is broken or unresponsive.
Furthermore, if users lose their Wi-Fi connection or exhaust their data, they will eventually recognize the problem and take corrective action, such as reconnecting to Wi-Fi or purchasing more data. Proactively informing them of the issue is a good practice that can potentially expedite the resolution process.
Now that we’ve established the rationale behind automatic retries, let’s explore how to implement them. We’ll focus on JavaScript, but these are just examples. The concepts are applicable to other languages and frameworks as well.
Implementing In JavaScript
For the browser, we’ll use the Fetch API. Since v18.0.0, Node.js bundles an inbuilt Fetch API implementation that provides a global fetch() method, like we have in browser environments. This implies that the code is consistent and can be used as-is in both environments, and in the case of Node.js, without any additional modules (dependencies).
async function fetchWithRetry(
url,
fetchOptions,
maxRetryCount = Infinity,
initialBackoffMs = 1000,
maxBackoffMs = 5000,
beforeRetry = (attemptsLeft, backoffMs, response, error) => {
if (response) {
console.log(
`Retrying ${url}: HTTP ${response.status}. ${attemptsLeft} ${
attemptsLeft === 1 ? "attempt" : "attempts"
} left (${backoffMs}ms backoff)`
);
}
if (error) {
console.log(
`Retrying ${url}: ${error.message}. ${attemptsLeft} ${
attemptsLeft === 1 ? "attempt" : "attempts"
} left (${backoffMs}ms backoff)`
);
}
},
exemptedHttpStatusCodes = [
400, 401, 402, 403, 405, 406, 407, 409, 410, 411, 412, 413, 414, 415, 416,
417, 418, 421, 422, 423, 424, 426, 428, 429, 431, 451, 501, 505, 506, 507,
508, 510, 511,
]
) {
const asyncSleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
let retryCount = 0;
let finalError;
let backoffMs = initialBackoffMs;
while (retryCount < maxRetryCount) {
const attemptsLeft = maxRetryCount - retryCount;
try {
const fetchFunc = (globalThis || window).inbuiltFetch || fetch;
const response = await fetchFunc(url, fetchOptions);
if (response.ok || exemptedHttpStatusCodes.includes(response.status)) {
return response;
}
finalError = new Error(`HTTP ${response.status} ${response.statusText}`);
finalError.response = response;
beforeRetry(attemptsLeft, backoffMs, response, null);
await asyncSleep(backoffMs);
} catch (error) {
finalError = error;
beforeRetry(attemptsLeft, backoffMs, null, error);
await asyncSleep(backoffMs);
}
backoffMs = Math.min(maxBackoffMs, backoffMs * 2);
retryCount++;
}
throw finalError;
}The fetchWithRetry() function wraps the inbuilt global fetch() method, providing built-in retry functionality. If a request to a specified URL fails, this function retries it a configurable number of times (maxRetryCount, line 4), which defaults to Infinity.
In between retry attempts, the function waits for a progressively increasing delay (exponential backoff). This delay starts at a user-defined value (initialBackoffMs, line 5) and never exceeds another user-defined value (maxBackoffMs, line 6), with default settings of 1000ms and 5000ms respectively.
fetchWithRetry() also accepts a custom function (beforeRetry, lines 7-23) that gets executed before each retry attempt. Users can modify this function to customize its behavior. The default implementation logs relevant retry information such as the URL, HTTP status code, or error message, the number of remaining attempts, and the delay for the next attempt.
Furthermore, there’s a configurable list of HTTP status codes (exemptedHttpStatusCodes, lines 24-28) for which the function skips retries. If a response with a status code from this list is received, or if the request returns a successful response (response.ok), the function immediately returns this response (line 44).
The delay between retry attempts is achieved using a utility function called asyncSleep (line 30), which essentially pauses the function execution for a specified duration, creating the required delay (lines 51, 56).
Finally, if all retry attempts fail, the function throws the error that occurred during the last attempt (line 63). The most recent error is stored in the finalError variable (line 33), which is updated each time an exception is encountered while attempting to fetch the URL (lines 47-48, 53).
Monkey Patching
The fetchWithRetry() function is implemented as a standalone function, but we can override the global fetch() function so that we don’t necessarily have to change our existing code (think of a code base with hundreds of API calls). This is known as “monkey patching”, and it’s a common practice in JavaScript. It can be detrimental if used carelessly, but it’s a useful technique in this case.
The following code snippet demonstrates how to monkey patch the global fetch() function in both Node.js and browser environments:
// Use the globalThis object if available (Node.js),
// otherwise use the window object (browser)
const context = globalThis || window;
// First, keep a copy of the original fetch function
// our fetchWithRetry function will use this when invoked
context.inbuiltFetch = (globalThis || window).fetch;
// Replace the global fetch function with the fetchWithRetry function
(globalThis || window).fetch = fetchWithRetry;The monkey patching code should be executed exactly once, and before any other code that uses the fetch() function. In the case of Node.js, it should be executed before any other code in the entry file (e.g. index.js or app.js). In the case of browser environments, it should be executed before any other code on the page (e.g. inlined in a script tag placed in the head tag).
TypeScript
If you’re monkey patching fetch() in TypeScript, you can override its signature to include the additional optional parameters accepted by fetchWithRetry(). Your typical .d.ts file should contain something like this:
// For Browser
declare interface Window {
fetch(
url: string,
fetchOptions: RequestInit,
maxRetryCount?: number,
initialBackoffMs?: number,
maxBackoffMs?: number,
beforeRetry?: (attemptsLeft: number, backoffMs: number, response: Response | null, error: Error | null) => void,
exemptedHttpStatusCodes?: number[]
): Promise<Response>;
}
// For Node.js
declare global {
export function fetch(
url: string,
fetchOptions: RequestInit,
maxRetryCount?: number,
initialBackoffMs?: number,
maxBackoffMs?: number,
beforeRetry?: (attemptsLeft: number, backoffMs: number, response: Response | null, error: Error | null) => void,
exemptedHttpStatusCodes?: number[]
): Promise<Response>;
}Example Usage
If you monkey patch the global fetch() function, you can use it as you normally would, and it will automatically retry failed requests. Here’s an example:
try {
const response = await fetch(
"https://jsonplaceholder.typicode.com/posts/1",
{ method: "GET" },
);
console.log("Response:", await response.json());
} catch (error) {
console.error("Last error:", error);
}Recall that maxRetryCount is set to Infinity by default in the fetchWithRetry() function, so the above API call will be retried until it succeeds. If you don’t want to monkey patch the global fetch() function, you can invoke the fetchWithRetry() function directly instead. Here’s an example:
try {
const response = await fetchWithRetry(
"https://jsonplaceholder.typicode.com/posts/1",
{ method: "GET" },
15 // maxRetryCount (not available in inbuilt fetch)
);
console.log("Response:", await response.json());
} catch (error) {
console.error("Last error:", error);
}Naturally, when applying monkey patching, it is also possible to pass additional arguments, just as we did with maxRetryCount in the direct invocation demonstrated in the second example above.
Demo In Browser
- Open a simple, unrestricted page like this one in a new tab. While on the page, open the developer tools (console). The shortcut is usually
F12. - Temporarily disconnect your device from the internet.
- Ensuring the console is in focus, paste the implementation code and hit
Enter. - Paste the monkey patching code and hit
Enter. - Paste any of the example usage code snippets and hit
Enter. - Reconnect to the internet. Without taking any extra action, the code will automatically fetch the data and log it.
Demo In Node.js
At the time of writing this, the latest LTS version of Node.js is v20.x.x. If you don’t have at least Node.js v18.0.0 installed, you can use nvm to install it. After verifying that you have Node.js v18.0.0 or higher installed with the command node --version, follow these steps:
- Create a new file and paste the implementation code.
- Append the monkey patching code to the same file.
- Append any of the example usage code snippets to the same file.
- Save the file as
fetch-with-retry.mjs. The.mjsextension is important, because we’re using top-levelawaitin the “example usage” code (available unflagged since Node v14.8). - Temporarily disconnect your device from the internet.
- Execute the file with
node fetch-with-retry.mjs, and then restore your internet connection within the retry window. Without taking any extra action, the code will automatically fetch the data and log it.
Here’s a screenshot of the output obtained from executing the second example snippet when the device is disconnected from the internet, and later reconnected, within a retry window of 15 attempts:
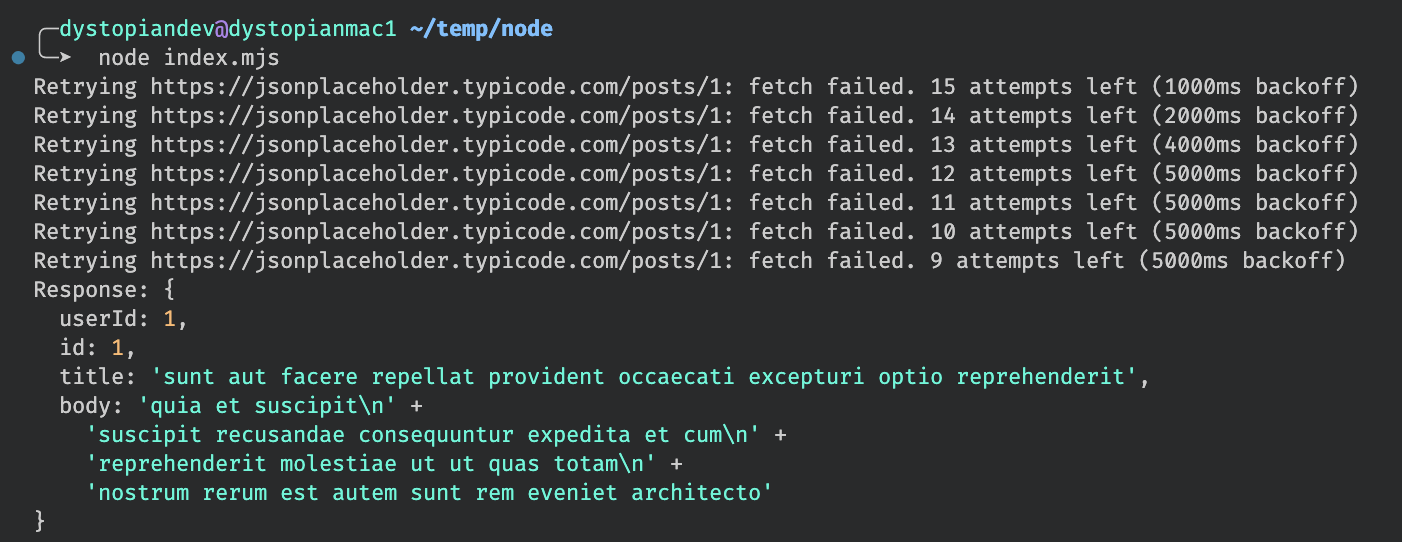
Notice how the backoff delay doubles with each attempt until it reaches the maximum value of 5000ms (5 seconds), at which point it remains constant for subsequent attempts. This behavior is determined by the default maxBackoffMs setting.
Exempted HTTP Status Codes
I mentioned earlier that there are situations where automatic retries should not be employed. In the implementations, I make use of a list of HTTP status codes that are exempted from automatic retries. This section explains why these exemptions are necessary.
4xx - Client Errors
-
400 (Bad Request): Indicates a malformed or invalid request from the client. Automatic retries won’t resolve the issue, as it’s likely a fundamental problem with the request itself.
-
401 (Unauthorized): Unauthorized access is a security concern. Retrying without proper authorization won’t change the outcome and may risk security breaches.
-
402 (Payment Required): This status implies a payment is needed for access. Retrying without addressing the payment requirement isn’t meaningful.
-
403 (Forbidden): Automatic retries won’t change the fact that the client lacks permission to access the requested resource.
-
405 (Method Not Allowed): The server indicates that the HTTP method used is not permitted for the requested resource. Retrying with the same method is unlikely to succeed.
-
406 (Not Acceptable): This status signifies that the server cannot produce a response matching the list of acceptable values defined in the request’s headers. Retrying won’t alter this condition.
-
407 (Proxy Authentication Required): If proxy authentication is necessary and hasn’t been provided, retrying without proper authentication won’t yield a different outcome.
-
409 (Conflict): Whether to retry on a 409 Conflict depends on the specific application logic and the nature of the conflict. In some cases, retries could exacerbate the problem, so caution is advised.
-
410 (Gone): This status indicates that the requested resource is permanently gone. Automatic retries will not resurrect it.
-
411 (Length Required): This status suggests that the server requires a valid Content-Length header in the request. Retrying without this header won’t change the outcome.
-
412 (Precondition Failed): The server has determined that a precondition set in the request has not been met. Retrying without meeting the precondition is unlikely to succeed.
-
413 (Payload Too Large): The server rejects the request because the payload size exceeds its limit. Retrying with the same payload size is counterproductive.
-
414 (URI Too Long): Similar to payload size issues, retrying with an excessively long URI is not a practical solution.
-
415 (Unsupported Media Type): If the server cannot process the request due to an unsupported media type, retrying with the same type is futile.
-
416 (Range Not Satisfiable): When the requested range is not satisfiable, automatic retries are unlikely to resolve the issue.
-
417 (Expectation Failed): This status indicates that the server cannot meet the requirements set by the “Expect” request header. Retrying without addressing these expectations won’t change the outcome.
-
418 (I’m a Teapot): While this status code is amusing, it’s not meant for practical use in APIs. Retrying won’t have any meaningful effect.
-
421 (Misdirected Request): Retrying after receiving this status code may not be beneficial, as it suggests a misconfiguration or server routing issue.
-
422 (Unprocessable Entity): The server is indicating that it cannot process the request due to semantic errors. Retrying without addressing these errors is unlikely to succeed.
-
423 (Locked): Whether to retry on a 423 Locked status depends on how long a resource is typically locked. If it’s a short-duration lock, retrying may be acceptable; otherwise, it may exacerbate the issue.
-
424 (Failed Dependency): This status suggests that the request failed due to a failure of a previous request. Retrying the current request without resolving the dependency is unlikely to succeed.
-
426 (Upgrade Required): The client must upgrade to a different protocol. Automatic upgrades may not be feasible, and manual intervention is typically required.
-
428 (Precondition Required): Fulfilling the required precondition on a second attempt may not be feasible without starting the request from the beginning. Caution is advised.
-
429 (Too Many Requests): Whether to retry a 429 Too Many Requests status depends on the rate limiting policies of the server. Retrying too quickly may violate these policies and lead to further restrictions.
-
431 (Request Header Fields Too Large): This status indicates that the request header fields are too large. Automatic retries with the same headers won’t resolve the issue.
-
451 (Unavailable For Legal Reasons): This status indicates that the resource is unavailable for legal reasons. Automatic retries are unlikely to change this situation.
5xx - Server Errors
-
501 (Not Implemented): This status code indicates that the server does not support the functionality required by the request. Automatic retries won’t enable unsupported features.
-
505 (HTTP Version Not Supported): When the server doesn’t support the HTTP version used in the request, retrying with the same version won’t yield a different result.
-
506 (Variant Also Negotiates): Automatic retries are unlikely to change the negotiation outcome for content variants.
-
507 (Insufficient Storage): If the server lacks storage space, automatic retries won’t free up space.
-
508 (Loop Detected): Retrying without addressing the loop detection issue is unlikely to resolve it.
-
510 (Not Extended): The server requires further extensions to fulfill the request. Automatic retries won’t add these required extensions.
-
511 (Network Authentication Required): This status indicates that network-level authentication is required. Retrying without proper authentication won’t change the outcome.
Final Thoughts
In summary, while automatic retries can improve user experience during network disruptions, they should be employed judiciously. HTTP status codes signaling client and server errors often represent issues that cannot be resolved by retries alone. Therefore, careful consideration of the specific error and its context is essential before deciding to automatically retry an API call. For instance, in the case of an HTTP status code 500, we may want to retry the request, but limit the number of retry attempts.